5 Ways Dremio is the “Easy Button” for Your Apache Iceberg Lakehouse


TRY THE 30 DAY FREE DREMIO CLOUD TRIAL TODAY
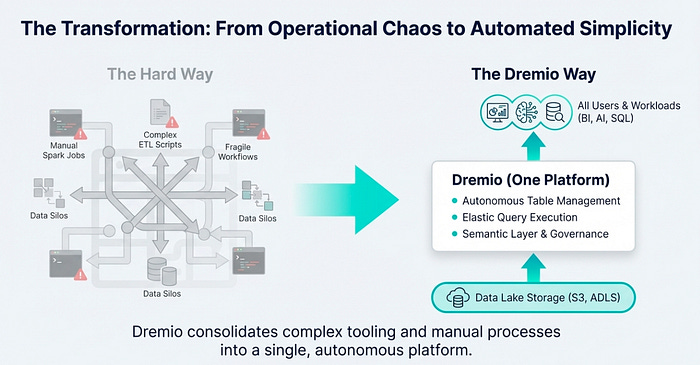
The data lakehouse architecture promises the best of both worlds: the massive scale and flexibility of a data lake combined with the performance and ACID transactions of a data warehouse. However, many data teams discover that this promise comes with a high operational cost. The reality of managing a lakehouse often involves constant performance tuning, manual file and partition management, and the complex overhead of configuring and scaling infrastructure. These tasks divert valuable time and resources away from the primary goal: deriving value from data.
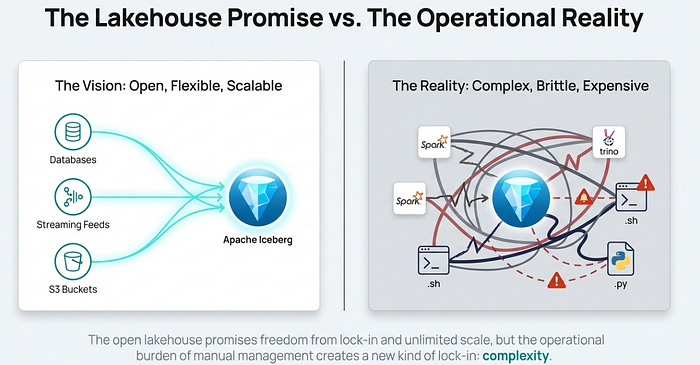
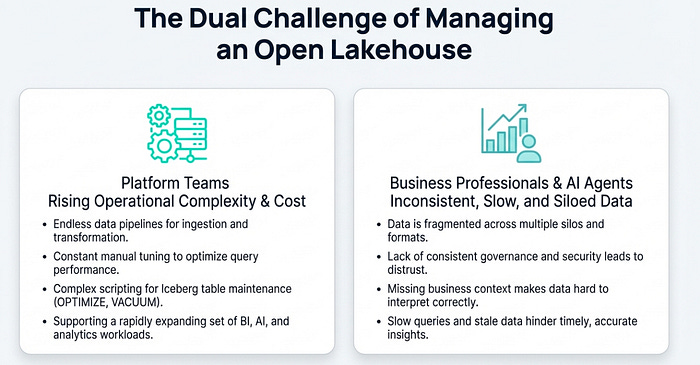
This is where Dremio steps in. It acts as the “easy button” for your lakehouse, automating the most challenging aspects of data management and operations, specifically for the Apache Iceberg table format. By handling the underlying complexity, Dremio allows your team to shift its focus from data management to data analysis and innovation.
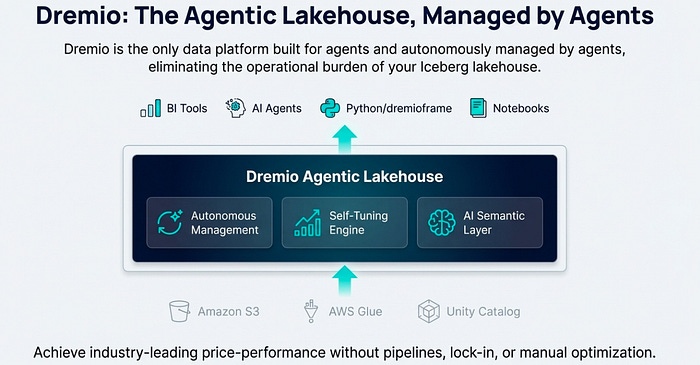
This article will explore five key Dremio features that deliver an effortless experience for building, managing, and querying your Iceberg-based data lakehouse.
1. “Set It and Forget It” Table Maintenance
In an active data lakehouse, Iceberg tables are constantly updated by ingestion jobs, streaming pipelines, and DML operations, which can create a large number of small data and metadata files. Over time, this accumulation degrades query performance because the engine must open and process an excessive number of files, adding significant overhead and latency to every query.
Dremio eliminates this performance drag by automating table maintenance for all Iceberg tables managed in its Open Catalog. This built-in process runs on Dremio-managed compute, requiring zero customer infrastructure to keep tables in a query-ready state. The automated tasks include not just compacting small data files and rewriting manifest files, but also optimizing the physical layout of the data itself through automated partitioning and clustering.
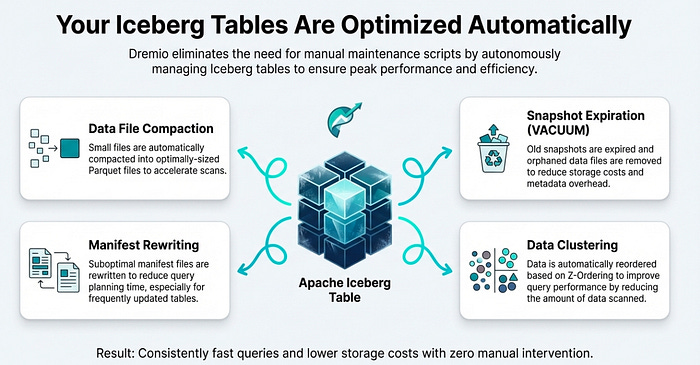
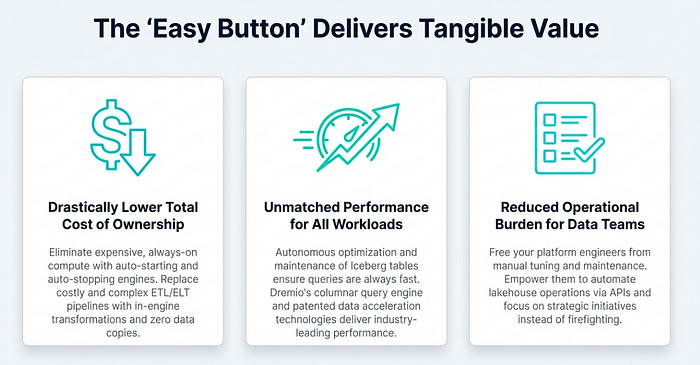
This automated approach is a true “easy button” for lakehouse operations, replacing entire categories of technical debt and operational risk. It removes the need for data engineers to write, schedule, and monitor complex, error-prone maintenance jobs using external tools like Apache Spark and Airflow. With Dremio, your Iceberg tables are always in an optimal state for high-speed queries by eliminating metadata overhead and reducing file open calls, all with no user intervention required.
“To optimize performance, Dremio automates table maintenance in the Open Catalog. This process compacts small files into larger ones… improving query speed while reducing storage costs.”
2. Automatic Query Acceleration That Just Works
Querying raw data directly from object storage can be slow, especially for complex analytical workloads. The traditional solution involves creating and maintaining materialized views or other acceleration structures, a manual process that requires deep expertise to identify the right candidates for optimization and keep them up-to-date.
Dremio revolutionizes this process with Reflections, and specifically, Autonomous Reflections. Instead of relying on manual intervention, Dremio acts like an expert DBA for your lakehouse. It automatically analyzes user query patterns to identify performance bottlenecks and then creates, manages, and maintains Reflections — physically optimized representations of your data — behind the scenes.
This powerful capability is available for Iceberg tables, tables using Delta Lake’s Universal Format (UniForm), Parquet datasets, and any views built upon them. The impact is profound: queries simply get faster over time without any action from data consumers or engineers. This stands in stark contrast to the manual, time-consuming effort of identifying optimization candidates, defining aggregation strategies, and managing refresh schedules, allowing architects to deliver high performance without building a complex and brittle acceleration layer.
“Learn how Dremio automatically learns your query patterns and manages Reflections to optimize performance accordingly.”
3. A True Open Catalog, Not a Walled Garden
Every Dremio project includes a built-in Open Catalog for managing Apache Iceberg tables. While this provides a robust, out-of-the-box solution for table management and governance, its most powerful feature is its commitment to openness.
The Dremio Open Catalog is not a proprietary, walled-garden system. It is fully compatible with the official Iceberg REST API standard, accessible via a stable endpoint: https://catalog.dremio.cloud/api/iceberg/v1/. This is a game-changer. It means other data processing engines and frameworks—like Apache Spark, Trino, and Apache Flink—can read and write data directly to the same Iceberg tables managed by Dremio.
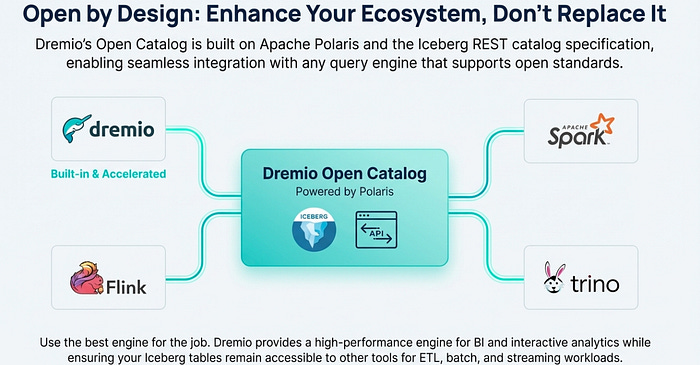
This feature is a powerful “easy button” because it ensures interoperability and prevents vendor lock-in. Your data engineering team can continue to use Spark for large-scale ETL transformations, and your stream processing team can use Flink for real-time ingestion, all while your analytics team uses Dremio’s lightning-fast query engine and semantic layer. Everyone works seamlessly from a single, consistent set of Iceberg tables, dramatically simplifying the data stack and fostering a truly open data architecture. With a truly open catalog accessible by any engine, the next challenge is keeping it continuously updated with fresh data — a task Dremio also simplifies.
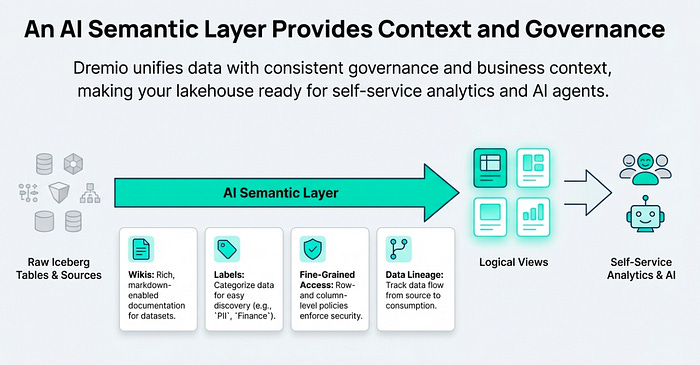
4. Effortless and Continuous Data Ingestion
A common challenge in maintaining a data lakehouse is keeping the data fresh and up-to-date. This typically requires building and managing complex data pipelines with external schedulers, event-driven triggers, and monitoring to load new data into tables as it arrives.
Dremio provides simple, powerful SQL-based tools to make data ingestion an effortless and continuous process for Iceberg tables. Dremio supports two primary methods for loading data:
• COPY INTO command: For one-time bulk loads, this simple SQL command can load data directly from CSV, JSON, or Parquet files into an existing Iceberg table.
• Autoingest Data: For continuous ingestion, users can create a “pipe” that automatically monitors a location and loads new files into the target Iceberg table. This feature currently targets Amazon S3 sources, reflecting Dremio’s cloud-native focus.
The autoingest feature, in particular, acts as a major “easy button” for data operations. It completely removes the need for external workflow managers or cloud-specific triggers (like AWS Lambda functions) to handle file arrival events. This ensures that your lakehouse data is kept current automatically and efficiently, allowing teams to build analytics on the freshest data possible without the engineering overhead of building and maintaining custom ingestion pipelines.
5. A Fully Managed Lakehouse, Without the Infrastructure Overhead
Running a high-performance query engine for a data lakehouse traditionally requires significant infrastructure expertise. Teams must set up, configure, scale, and manage the underlying compute resources, a task that can become a full-time job and a distraction from data-centric goals.
Dremio Cloud operates on a shared responsibility model that abstracts away nearly all of this infrastructure burden. Dremio’s architecture is divided into three planes. The control and execution planes are fully hosted and managed by Dremio, while the data plane , your actual data in object storage , remains in your cloud account, ensuring you retain full ownership and control.
This delivers several “easy button” benefits:
• Dremio-Managed Storage: For users who want to get started immediately, Dremio offers a managed storage option that requires zero setup or configuration of an object storage bucket.
Autoscaling: Dremio dynamically manages the query workload for you. Based on user-set parameters such as minimum/maximum engine replicas (
Size) or the idle shutdown period (Last Replica Auto-Stop), Dremio automatically starts and stops engine replicas to handle fluctuating query demand, ensuring optimal performance and cost-efficiency without manual intervention.
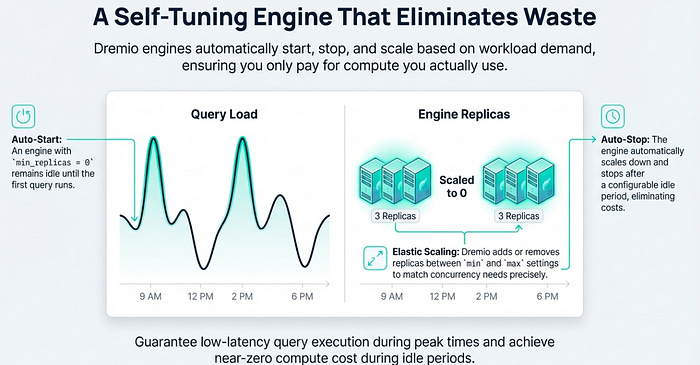
This model provides the power of a massively parallel processing (MPP) query engine without the associated management headaches. Your team is freed from the complexities of cloud infrastructure, allowing them to provision and use a world-class lakehouse query engine with just a few clicks.
Conclusion: Focus on Your Data, Not Your Data Lake
Dremio fundamentally changes the lakehouse experience by removing the operational friction that so often hinders data teams. Through intelligent automation and a fully managed service, Dremio delivers a true “easy button” for the most complex aspects of running an Apache Iceberg lakehouse.
By seamlessly handling table maintenance, automatically accelerating queries, simplifying data ingestion, and managing all the underlying infrastructure, Dremio frees your data teams to focus on what they do best: unlocking insights and creating value.
If the complexity of managing your lakehouse disappeared, what new, more valuable questions would you ask of your data?
Great breakdown of how automation shifts the lakehouse burden. The autonomous reflections piece is especially underrated because manually tuning materialized views for query patterns becomes a full-time job at scale. Ran into this at a fintech company where we spent 2 engineers just chasing query slowdowns untilwe automated most of the tuning layer. The open catalog compatibility with Spark and Flink is kinda clutch for avoiding vendor lock-in tho.